
Optimising the data path for Earth-observation inference at scale
Whether it’s for monitoring floods, assessing agricultural conditions, or detecting wildfires, every Earth-Observation AI system based on satellite remote-sensing data shares a common task: given the area of interest and a time window, find the products that cover it and turn them into model inputs.
Intuitively, a live discovery approach appears attractive: products are discovered, retrieved, and prepared as part of each model run, avoiding the complexity of maintaining a separate data layer.

Satellite-Based Water Change Detection: Monitoring Anomalies
Water change detection is one of the most critical applications of modern remote sensing. As climate volatility increases, the ability to accurately quantify surface water extent and soil moisture levels has become a priority for hydrologists, agricultural practitioners, policymakers and urban planners alike. Utilizing multi-spectral (Sentinel-2) and Synthetic Aperture Radar (Sentinel-1) data, we can now map hydrologic anomalies (droughts or floods) with unprecedented precision.
In the DaFab project, the water change detection workflow is used to enrich satellite data with additional parameters that indicate flood or drought in the scenes. It helps in optimizing the search, automating the selection of the past flood or drought events visible in Sentinel-1 / Sentinel-2 images and finally monitoring, analysing the affected areas from the generated water masks.
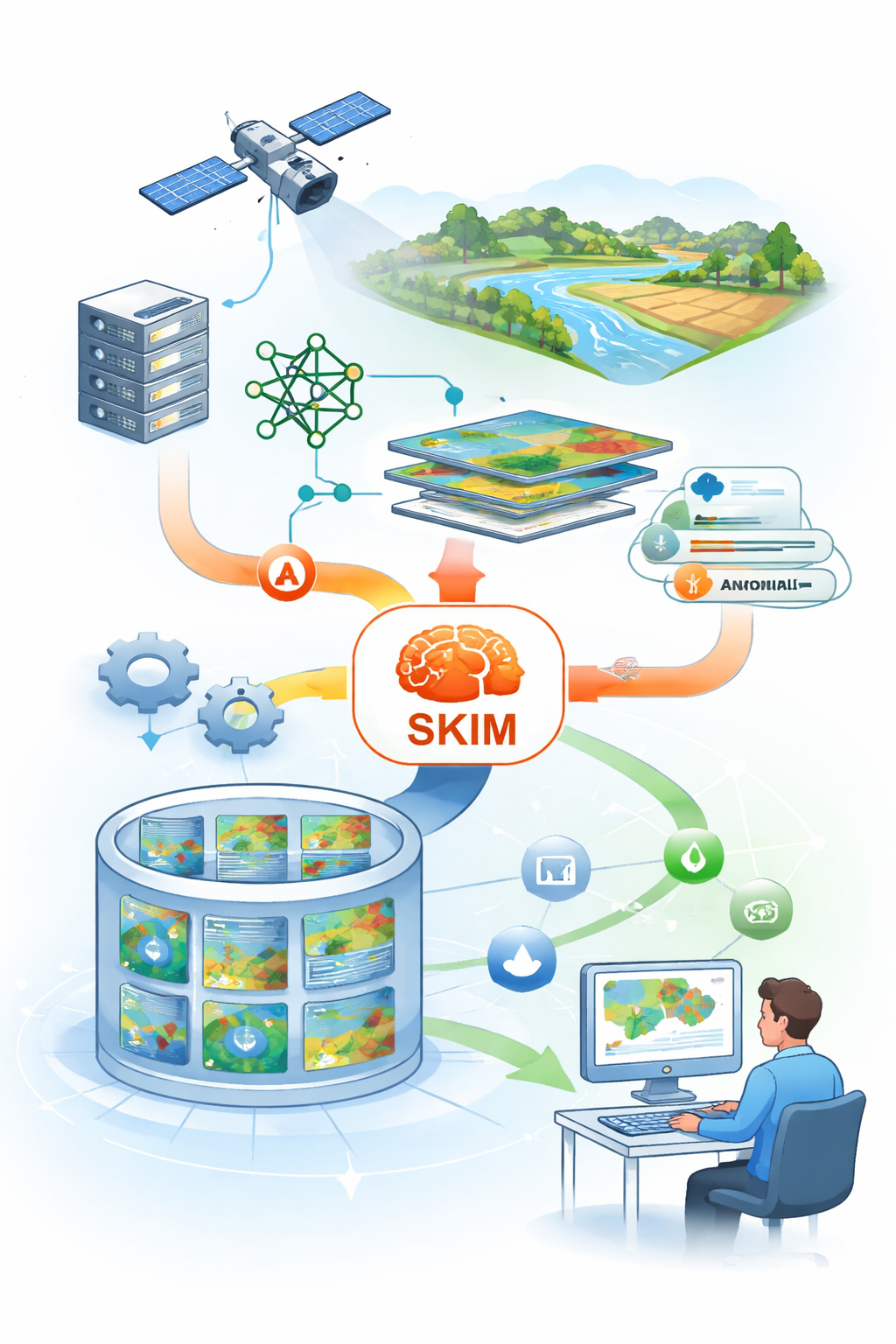
From AI Outputs to Searchable Knowledge
The role of SKIM in DaFab system architecture
Introduction: Turning a Copernicus data scale archive into something you can search
Copernicus has grown into an archive where the limiting factor is rarely the availability of pixels, but the ability to find the right ones. To do so, users still have to start from copernicus product descriptors (e.g. Sentinel-2 tile, date, processing level, etc…) and only later test whether the data contains the signal of interest. DaFab system addresses this gap by generating secondary, AI‑derived metadata at scale and exposing it as a discovery surface, so that users can begin with a thematic question instead of beginning with file selection (e.g. “How many agriculture parcels are there ?” in smart-agriculture thematic and “Where can I find water anomalies ?” for water-analysis one).